
일단 셀레니움 기본 코드를 써놨습니다.
implicitly_wait 이 부분은 3초 쉰다고 말씀드렸는데, 페이지가 로드 되는 것 기다린다 라고 생각하시면 됩니다. 크게 신경쓸 부분은 아닙니다.
자, 그렇다면 이제 계속 해보는데, 오늘의 유머 사이트를 크롤링 해 봅니다.

여기까지 해서, html 태그를 다 뽑아올 수 있고

여기까지 해서 제목들 뽑아 올 수 있습니다.
여기에서 클릭을 통해서, 다양한 태그들을 한번 뽑아와보겠습니다.
아래와 같이 id를 찾아서 클릭해서, 사용할 수 있습니다.
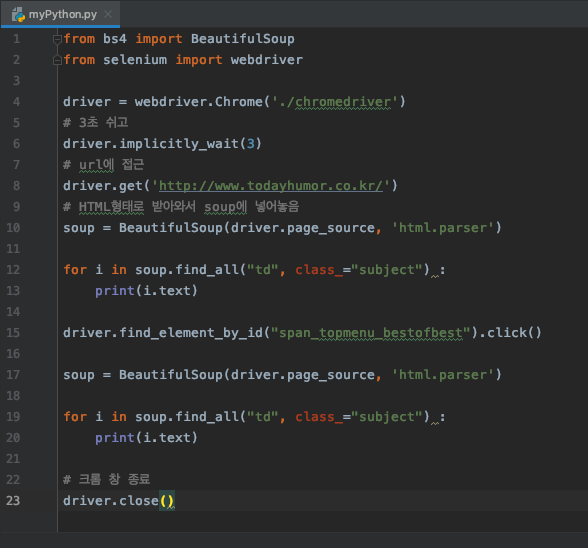
코드
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
# 3초 쉬고
driver.implicitly_wait(3)
# url에 접근
driver.get('http://www.todayhumor.co.kr/')
# HTML형태로 받아와서 soup에 넣어놓음
# 오늘의 유머 사이트로 접속해서 나오는 제목들을 다 크롤링 한 다음
soup = BeautifulSoup(driver.page_source, 'html.parser')
for i in soup.find_all("td", class_="subject") :
print(i.text)
# 그 다음 베스트오브베스트 라는 버튼을 눌러서, 나오는 게시글들의 제목을 크롤링
driver.find_element_by_id("span_topmenu_bestofbest").click()
print("구분선 --- ------")
soup = BeautifulSoup(driver.page_source, 'html.parser')
for i in soup.find_all("td", class_="subject") :
print(i.text)
# 자유게시판 제목 크롤링
print("구분선2 --- ------")
driver.find_element_by_id("span_topmenu_freeboard").click()
for i in soup.find_all("td", class_="subject") :
print(i.text)
print("구분선3 --- ------")
# driver.close()
끝 :)
'인프런 - 강의 > 초간단 초스피드 데이터 수집 (파이썬 크롤링)' 카테고리의 다른 글
| 11 - 드디어 엑셀로 저장, 불러오기 (0) | 2019.12.23 |
|---|---|
| 10 - 간단한 텍스트 가공법 (0) | 2019.12.23 |
| 8- selenium 사용법 (0) | 2019.12.21 |
| 7 - 뉴스 기사 내용까지 추출하기 (0) | 2019.12.20 |
| 6 - url 링크 찾아내서 크롤링 (0) | 2019.12.20 |