개복치개발자 강의는 아래의 링크에서 확인할 수 있습니다.
개복치개발자 | Linktree
uyalae@naver.com
linktr.ee
가끔 beautifulSoup로 크롤링을 할 때 크롤링이 막히는 경우가 종종 있습니다.
그 때 사이트에서 user-agent정보를 확인해서, 이 정보가 없는 경우 막는 방법으로 크롤링을 차단하는데
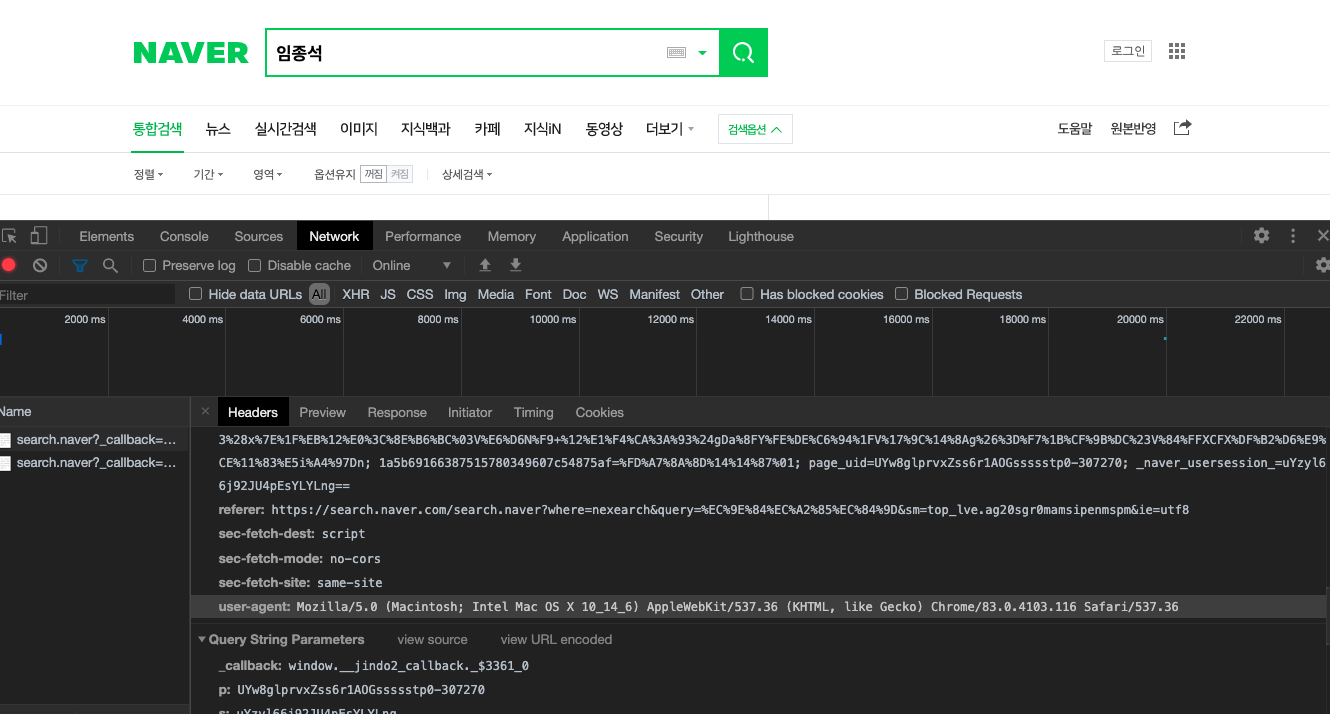
크롬에서 network -> Headers에 있는 user-agent 정보입니다.
저 정보를 아래의 사이트에서 받아올 수 있습니다.
http://www.useragentstring.com/pages/useragentstring.php
UserAgentString.com - List of User Agent Strings
www.useragentstring.com
아래와 같이 사용합니다.
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = 'https://search.shopping.naver.com/search/all?query=%EC%9C%A1%EC%95%84%EC%9A%A9%ED%92%88'
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, 'html.parser')
셀레니움에서는 아래와 같이 사용합니다.
options = webdriver.ChromeOptions()
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko")
driver = webdriver.Chrome("./chromedriver", options = options)
'개발 > 잡다개발' 카테고리의 다른 글
| 파이썬 Non-ASCII Character (0) | 2020.07.09 |
|---|---|
| EC2 셀레니움 배포 (0) | 2020.07.09 |
| selenium window size (0) | 2020.07.01 |
| selenium tab change (0) | 2020.07.01 |
| python logger (0) | 2020.06.30 |