이제 실전적으로 한번 크롤링을 해 보겠습니다.
네이버 뉴스로 들어가면, 나오는 뉴스 기사들을 beatifulSoup를 이용해서 크롤링 해 보겠습니다.
다음시간에는 셀레니움을 사용해서 크롤링해 보겠습니다.
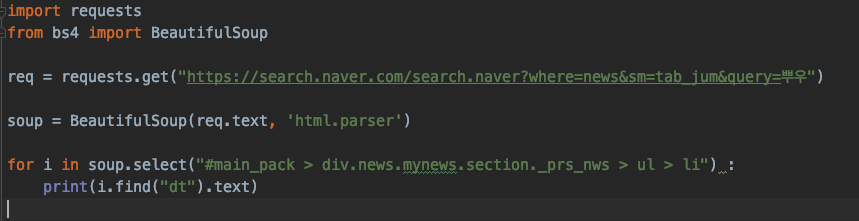

이렇게 네이버 인기 검색어를 뽑아낼 수도 있구요
url의 query="" 이 부분의 값을 약간 변경해서 검색어를 변경할 수도 있습니다.
그렇다면, 얘네들의 값을 5페에지까지 가져와볼까요?
url의 값을 받아와서 한번 돌려줍니다.
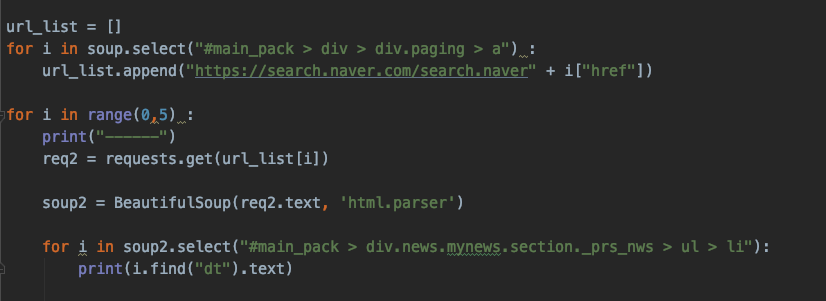

이렇게 해서 크롤링 할 수 있습니다. 아래는 전체 코드
import requests
from bs4 import BeautifulSoup
req = requests.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query=뿌우")
soup = BeautifulSoup(req.text, 'html.parser')
for i in soup.select("#main_pack > div.news.mynews.section._prs_nws > ul > li") :
print(i.find("dt").text)
url_list = []
for i in soup.select("#main_pack > div > div.paging > a") :
url_list.append("https://search.naver.com/search.naver" + i["href"])
for i in range(0,5) :
print("------")
req2 = requests.get(url_list[i])
soup2 = BeautifulSoup(req2.text, 'html.parser')
for i in soup2.select("#main_pack > div.news.mynews.section._prs_nws > ul > li"):
print(i.find("dt").text)
'인프런 - 강의 > 초간단 초스피드 데이터 수집 (파이썬 크롤링)' 카테고리의 다른 글
| 15 - 정리 (0) | 2019.12.23 |
|---|---|
| 14 - 실전 크롤링 연습 selenium (0) | 2019.12.23 |
| 12 - 드디어 엑셀로 저장, 불러오기 (2) (0) | 2019.12.23 |
| 11 - 드디어 엑셀로 저장, 불러오기 (0) | 2019.12.23 |
| 10 - 간단한 텍스트 가공법 (0) | 2019.12.23 |