네이버 쇼핑에 있는 초밥세트 제목들을 가져와겠습니다.
여기 사이트의 것들도 가져오고 옆의 항목들(가격비교, 네이버페이, 백화점쇼핑, 핫딜) 등등도 가져올 수 있습니다.
셀레니움을 사용해서 작업해볼껀데 한번 같이 해보겠습니다.

일단 아래와 같은 코드로 정보를 가져올 수 있습니다.
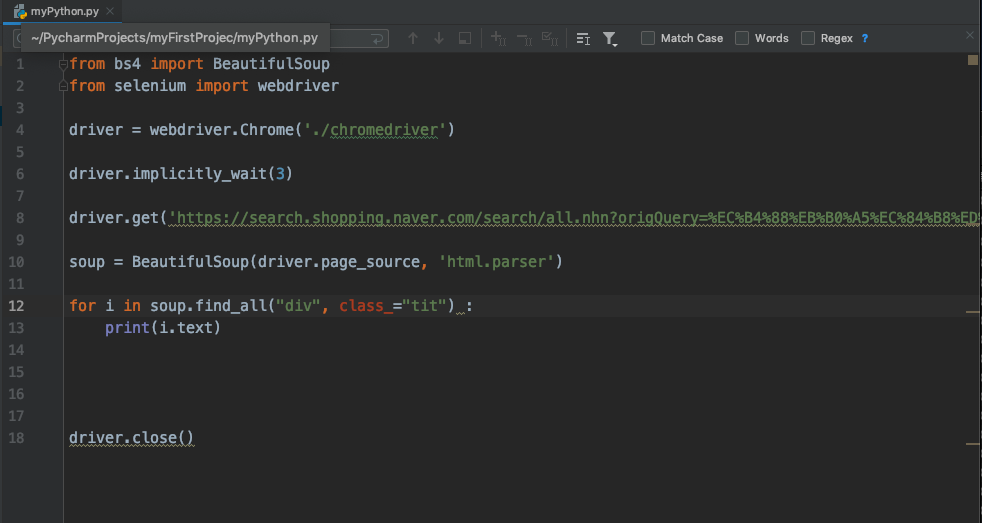

그런데 검색을 해 보면, 가격비교에 있는 것들의 내용이 안 나옵니다.
그래서 find_element_by_class_name으로 클래스 명을 찾아서 click을 해주고 난 다음 크롤링을 진행합니다.

전체 코드
from bs4 import BeautifulSoup
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.implicitly_wait(3)
driver.get('https://search.shopping.naver.com/search/all.nhn?origQuery=%EC%B4%88%EB%B0%A5%EC%84%B8%ED%8A%B8&pagingIndex=1&pagingSize=40&viewType=list&sort=rel&frm=NVSHTTL&query=%EC%B4%88%EB%B0%A5%EC%84%B8%ED%8A%B8')
soup = BeautifulSoup(driver.page_source, 'html.parser')
for i in soup.find_all("div", class_="tit") :
print(i.text)
driver.find_element_by_class_name("_productSet_model").click()
soup = BeautifulSoup(driver.page_source, 'html.parser')
print("구분선입니당")
for i in soup.find_all("div", class_="tit") :
print(i.text)'인프런 - 강의 > 초간단 초스피드 데이터 수집 (파이썬 크롤링)' 카테고리의 다른 글
| 15 - 정리 (0) | 2019.12.23 |
|---|---|
| 13 - 실전 크롤링 beatifulSoup (0) | 2019.12.23 |
| 12 - 드디어 엑셀로 저장, 불러오기 (2) (0) | 2019.12.23 |
| 11 - 드디어 엑셀로 저장, 불러오기 (0) | 2019.12.23 |
| 10 - 간단한 텍스트 가공법 (0) | 2019.12.23 |