https://www.kaggle.com/uciml/pima-indians-diabetes-database
Pima Indians Diabetes Database
Predict the onset of diabetes based on diagnostic measures
www.kaggle.com
Pima 인디언 관련 당뇨병 데이터를 보고 당뇨병을 예측하는 것입니다.
Content
The datasets consists of several medical predictor variables and one target variable, Outcome. Predictor variables includes the number of pregnancies the patient has had, their BMI, insulin level, age, and so on.
함유량
데이터 세트는 여러 의학적 예측 변수와 하나의 목표 변수 인 결과로 구성됩니다. 예측 변수에는 환자의 임신 횟수, BMI, 인슐린 수준, 연령 등이 포함됩니다.
데이터들은
Pregnancies
Number of times pregnant
Glucose
Plasma glucose concentration a 2 hours in an oral glucose tolerance test
BloodPressure
Diastolic blood pressure (mm Hg)
SkinThickness
Triceps skin fold thickness (mm)
Insulin
2-Hour serum insulin (mu U/ml)
BMI
Body mass index (weight in kg/(height in m)^2)
DiabetesPedigreeFunction
Diabetes pedigree function
Age
Age (years)
Outcome
Class variable (0 or 1) 268 of 768 are 1, the others are 0
와 같이 나타납니다.

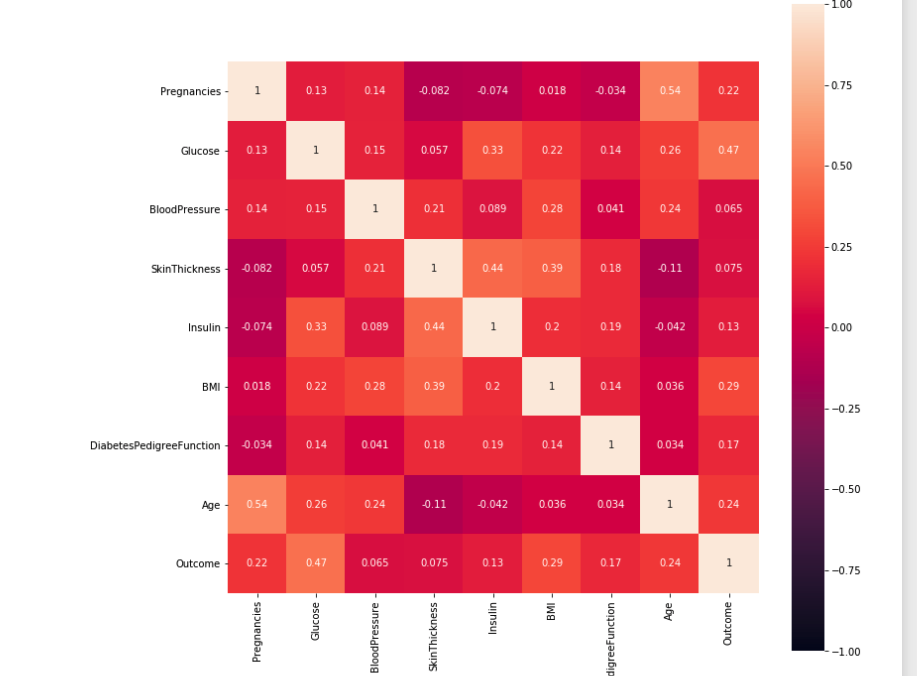



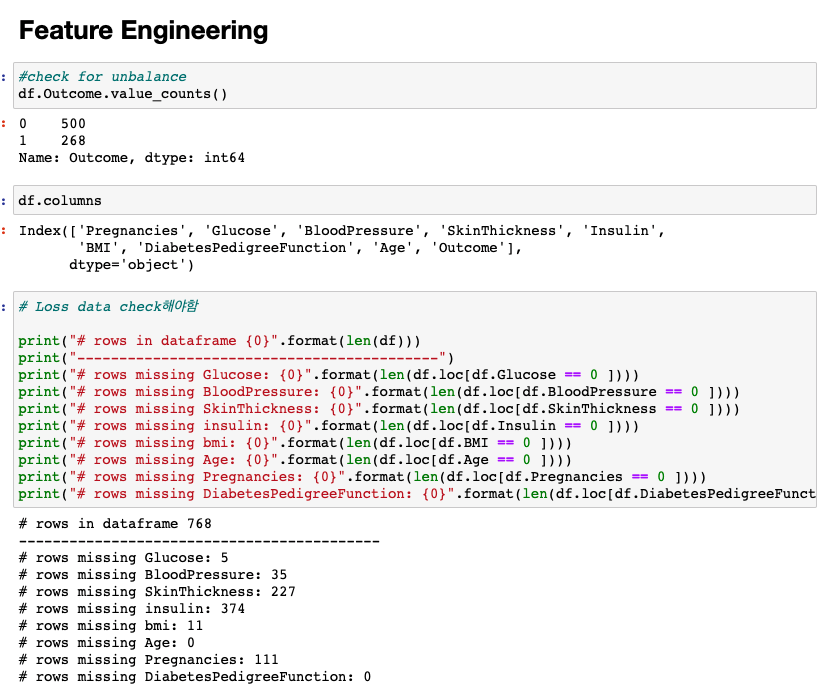






참고
[1] - https://github.com/cosmicudemy/ML_Casestudies
'개발 > Kaggle' 카테고리의 다른 글
| bar 비교차트 (0) | 2020.05.08 |
|---|---|
| bar 비교차트 (0) | 2020.05.03 |
| Caterpillar Tube Pricing Predicting (0) | 2020.04.21 |
| SMOTE(synthetic minority oversampling technique) (0) | 2020.04.21 |
| Confusion Matrix (0) | 2020.04.21 |