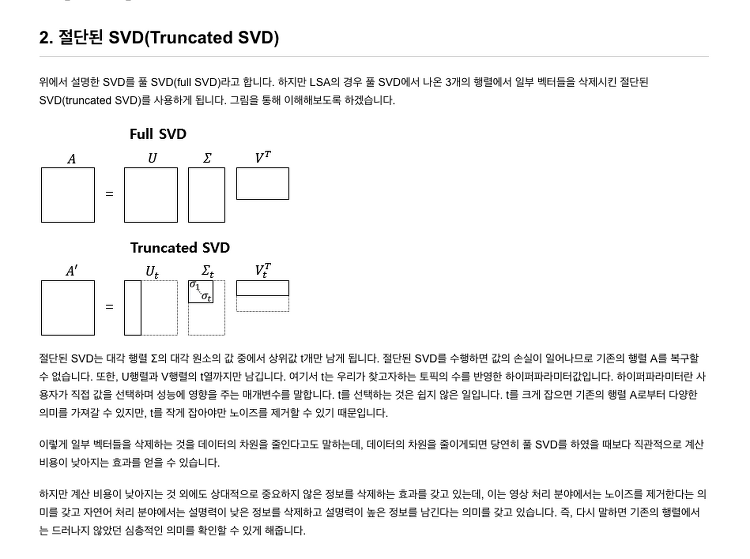
도커를 공부하려고 찾아보다 보면, 이미지와 컨테이너라는 말이 많이 나옵니다. 이 단어들로 인해 도커에 대한 이해도가 더 낮아지는 것 같기도 합니다. 일단 이미지부터 알아보겠습니다. 위의 사진처럼 Image.jpg 이런 이미지가 아니라 쉽게 설명하면, 응용 프로그램? 같은거라고 생각하시면 됩니다. OS일 수도 있고, Python일 수도 있고, mysql일 수도 있고,mongodb일 수도 있습니다. 자 이제 이미지(ubuntu)를 사용한다고 생각해보면, 이 이미지를 가지고 우분투 어떤 환경에서 어떻게 실행시킬지 정해놓고 얘를 실앻을 하면 컨테이너가 된다고 생가각하면 됩니다.