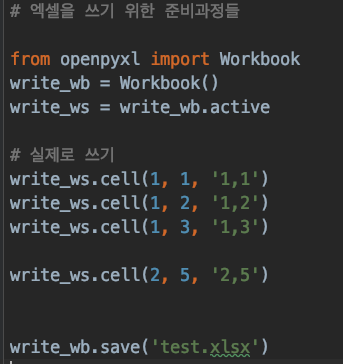
이번에는 엑셀로 저장하는 것을 해 보겠습니다. 엑셀에 글을 써서 test.xlsx라고 저장하면 이렇게 콤마로 찍을 수 있습니다. 이렇게 반복문을 사용할 수도 있고 이제 크롤링 해온 내용들을 한번 엑셀에 저장해보겠습니다. 아래는 코드 입니다. # 엑셀을 쓰기 위한 준비과정들 import requests from bs4 import BeautifulSoup req = requests.get('http://www.naver.com') soup = BeautifulSoup(req.text, 'html.parser') naver_list = [] for i in soup.select("#PM_ID_ct > div.header > div.section_navbar > div.area_hotkeyword.PM_CL_..